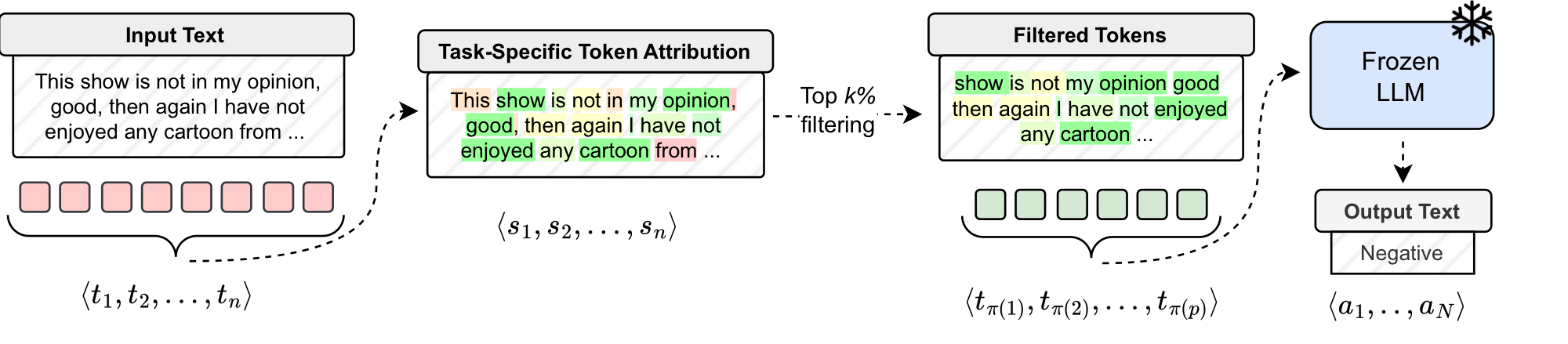
| Model | Attribution | $k\%$ | CLS | SUM | QA | RSN | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc | F1 | BLEU | R-1 | R-2 | R-L | BERT | METEOR | Acc | pass@1 | |||
| Llama-3 8B | N/A | 100 | 0.949 | 0.949 | 0.020 | 0.232 | 0.073 | 0.193 | 0.872 | 0.335 | 0.813 | 0.786 |
| GlobEnc | 80 | 0.942 | 0.942 | 0.017 | 0.226 | 0.069 | 0.189 | 0.871 | 0.330 | 0.798 | 0.500 | |
| 60 | 0.942 | 0.942 | 0.015 | 0.220 | 0.064 | 0.181 | 0.870 | 0.319 | 0.754 | 0.243 | ||
| 50 | 0.921 | 0.921 | 0.013 | 0.213 | 0.057 | 0.175 | 0.868 | 0.303 | 0.716 | 0.146 | ||
| DecompX | 80 | 0.936 | 0.936 | 0.015 | 0.218 | 0.061 | 0.179 | 0.869 | 0.311 | 0.747 | 0.652 | |
| 60 | 0.900 | 0.900 | 0.014 | 0.206 | 0.055 | 0.169 | 0.866 | 0.286 | 0.681 | 0.425 | ||
| 50 | 0.868 | 0.868 | 0.012 | 0.198 | 0.048 | 0.161 | 0.864 | 0.270 | 0.670 | 0.265 | ||
| Llama-3 70B | N/A | 100 | 0.953 | 0.953 | 0.020 | 0.235 | 0.073 | 0.196 | 0.876 | 0.333 | 0.874 | 0.919 |
| GlobEnc | 80 | 0.948 | 0.948 | 0.018 | 0.235 | 0.071 | 0.195 | 0.875 | 0.331 | 0.862 | 0.669 | |
| 60 | 0.943 | 0.943 | 0.017 | 0.231 | 0.068 | 0.192 | 0.874 | 0.329 | 0.838 | 0.362 | ||
| 50 | 0.938 | 0.938 | 0.016 | 0.228 | 0.065 | 0.189 | 0.873 | 0.316 | 0.816 | 0.231 | ||
| DecompX | 80 | 0.949 | 0.949 | 0.017 | 0.226 | 0.065 | 0.187 | 0.870 | 0.316 | 0.839 | 0.818 | |
| 60 | 0.891 | 0.891 | 0.015 | 0.215 | 0.057 | 0.176 | 0.868 | 0.292 | 0.797 | 0.587 | ||
| 50 | 0.839 | 0.837 | 0.014 | 0.209 | 0.054 | 0.171 | 0.866 | 0.281 | 0.770 | 0.409 | ||
| GPT-3.5 | N/A | 100 | 0.949 | 0.949 | 0.039 | 0.282 | 0.093 | 0.237 | 0.889 | 0.359 | 0.779 | 0.772 |
| GlobEnc | 80 | 0.945 | 0.945 | 0.017 | 0.176 | 0.056 | 0.146 | 0.874 | 0.291 | 0.753 | 0.498 | |
| 60 | 0.925 | 0.925 | 0.015 | 0.172 | 0.052 | 0.141 | 0.874 | 0.285 | 0.716 | 0.264 | ||
| 50 | 0.918 | 0.918 | 0.014 | 0.170 | 0.049 | 0.140 | 0.873 | 0.278 | 0.705 | 0.158 | ||
| DecompX | 80 | 0.942 | 0.942 | 0.036 | 0.268 | 0.084 | 0.225 | 0.888 | 0.337 | 0.704 | 0.660 | |
| 60 | 0.724 | 0.704 | 0.031 | 0.253 | 0.073 | 0.210 | 0.885 | 0.311 | 0.648 | 0.419 | ||
| 50 | 0.642 | 0.595 | 0.027 | 0.241 | 0.065 | 0.200 | 0.882 | 0.291 | 0.619 | 0.288 | ||
| Gemini 2.0 Flash Thinking | N/A | 100 | 0.952 | 0.952 | 0.034 | 0.262 | 0.081 | 0.219 | 0.885 | 0.345 | 0.880 | 0.956 |
| GlobEnc | 80 | 0.947 | 0.947 | 0.031 | 0.252 | 0.081 | 0.212 | 0.882 | 0.344 | 0.879 | 0.704 | |
| 60 | 0.934 | 0.934 | 0.029 | 0.247 | 0.077 | 0.208 | 0.881 | 0.335 | 0.846 | 0.423 | ||
| 50 | 0.920 | 0.919 | 0.026 | 0.239 | 0.071 | 0.199 | 0.879 | 0.322 | 0.827 | 0.277 | ||
| DecompX | 80 | 0.855 | 0.852 | 0.031 | 0.251 | 0.075 | 0.209 | 0.883 | 0.328 | 0.856 | 0.856 | |
| 60 | 0.713 | 0.690 | 0.028 | 0.236 | 0.068 | 0.194 | 0.878 | 0.307 | 0.795 | 0.665 | ||
| 50 | 0.627 | 0.571 | 0.024 | 0.225 | 0.059 | 0.185 | 0.876 | 0.283 | 0.774 | 0.463 | ||
| o3-mini | N/A | 100 | 0.957 | 0.957 | 0.023 | 0.221 | 0.065 | 0.182 | 0.860 | 0.297 | 0.845 | 0.961 |
| GlobEnc | 80 | 0.956 | 0.956 | 0.020 | 0.216 | 0.060 | 0.176 | 0.859 | 0.290 | 0.826 | 0.724 | |
| 60 | 0.941 | 0.941 | 0.019 | 0.212 | 0.059 | 0.173 | 0.858 | 0.282 | 0.802 | 0.462 | ||
| 50 | 0.932 | 0.932 | 0.018 | 0.204 | 0.055 | 0.166 | 0.857 | 0.272 | 0.785 | 0.332 | ||
| DecompX | 80 | 0.842 | 0.839 | 0.020 | 0.208 | 0.056 | 0.170 | 0.858 | 0.273 | 0.787 | 0.850 | |
| 60 | 0.727 | 0.707 | 0.018 | 0.195 | 0.049 | 0.159 | 0.854 | 0.253 | 0.724 | 0.679 | ||
| 50 | 0.641 | 0.593 | 0.017 | 0.187 | 0.045 | 0.152 | 0.853 | 0.236 | 0.686 | 0.533 | ||
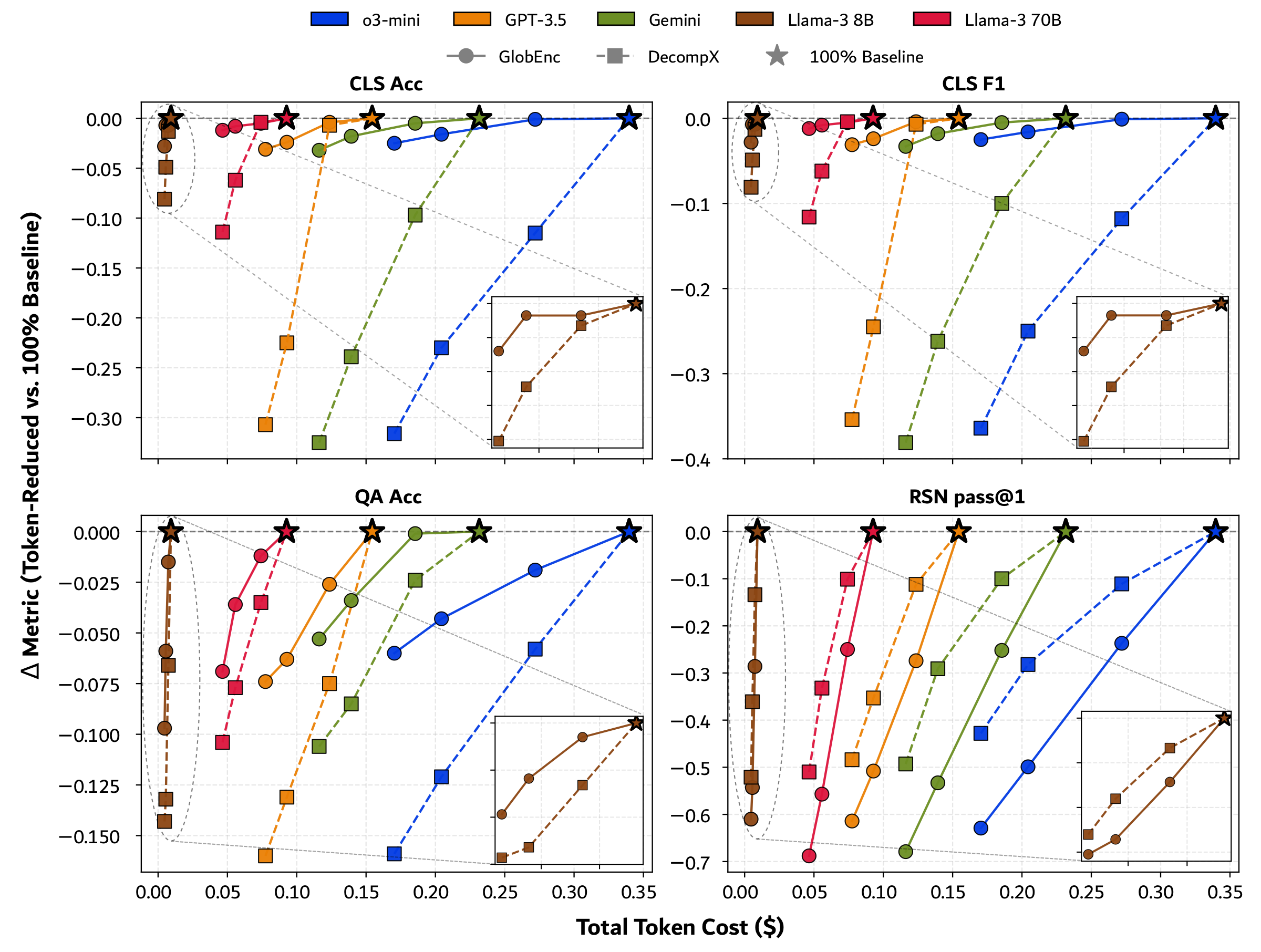
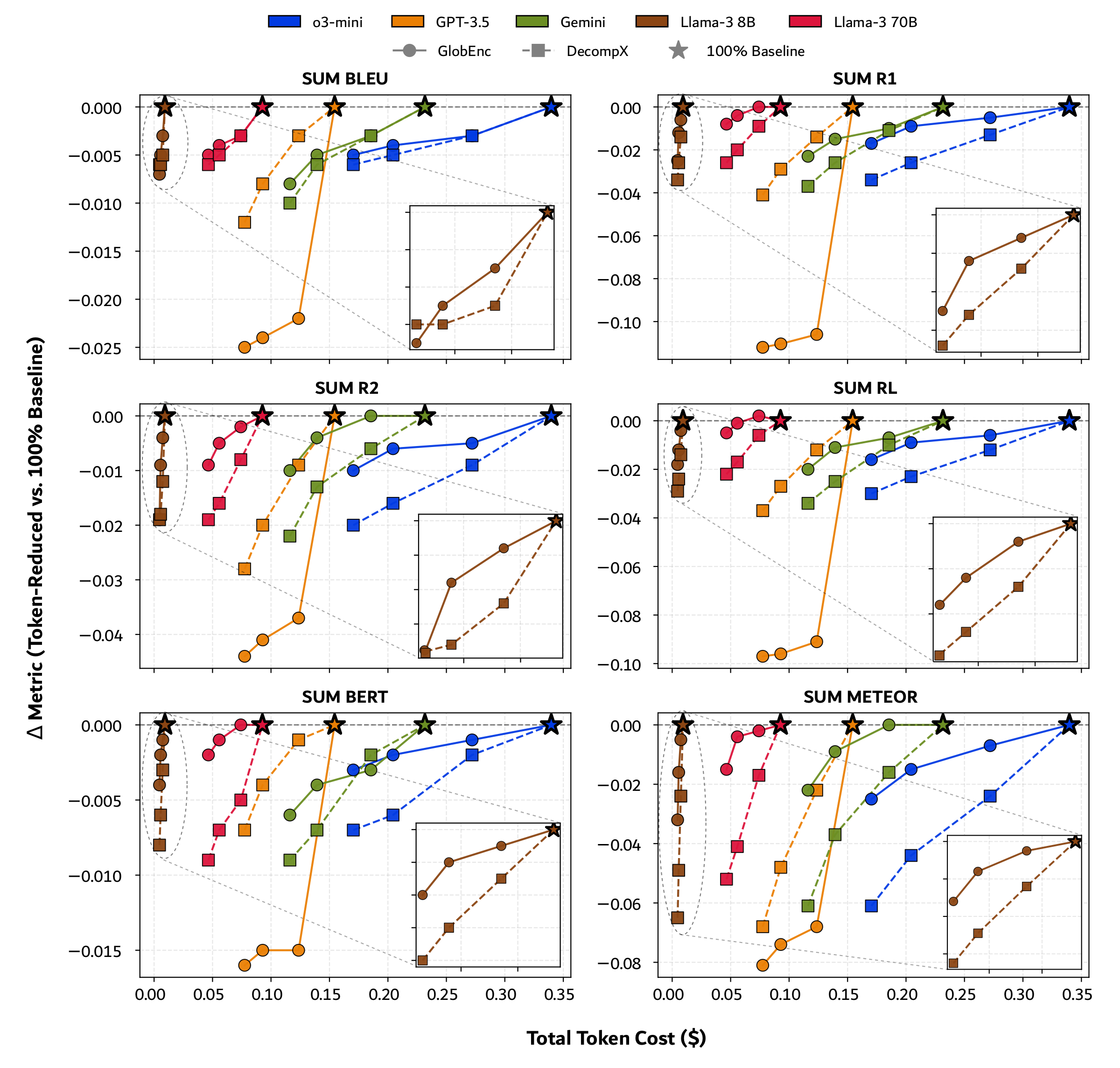
Table 1. Impact of the two variants of FrugalPrompt retaining $k\%$ tokens on baseline LLM performance across text classification (CLS), summarization (SUM), question answering (QA), and reasoning (RSN). Gray = baseline, Blue = best prompt-reduced per model. Bold = highest overall, Underline = best prompt-reduced overall.